
엔비디아가 2026년 4월 28일 Nemotron 3 Nano Omni를 공개했다. 한 모델 안에서 텍스트·이미지·비디오·오디오 네 가지 입력을 동시에 받는 오픈 가중치 멀티모달 모델이다. 총 파라미터 30B 중 토큰당 3B만 활성화되는 하이브리드 Mamba-Transformer Mixture-of-Experts 구조라, 25GB VRAM 한 장짜리 GPU에서도 4-bit 양자화로 돌릴 수 있다.
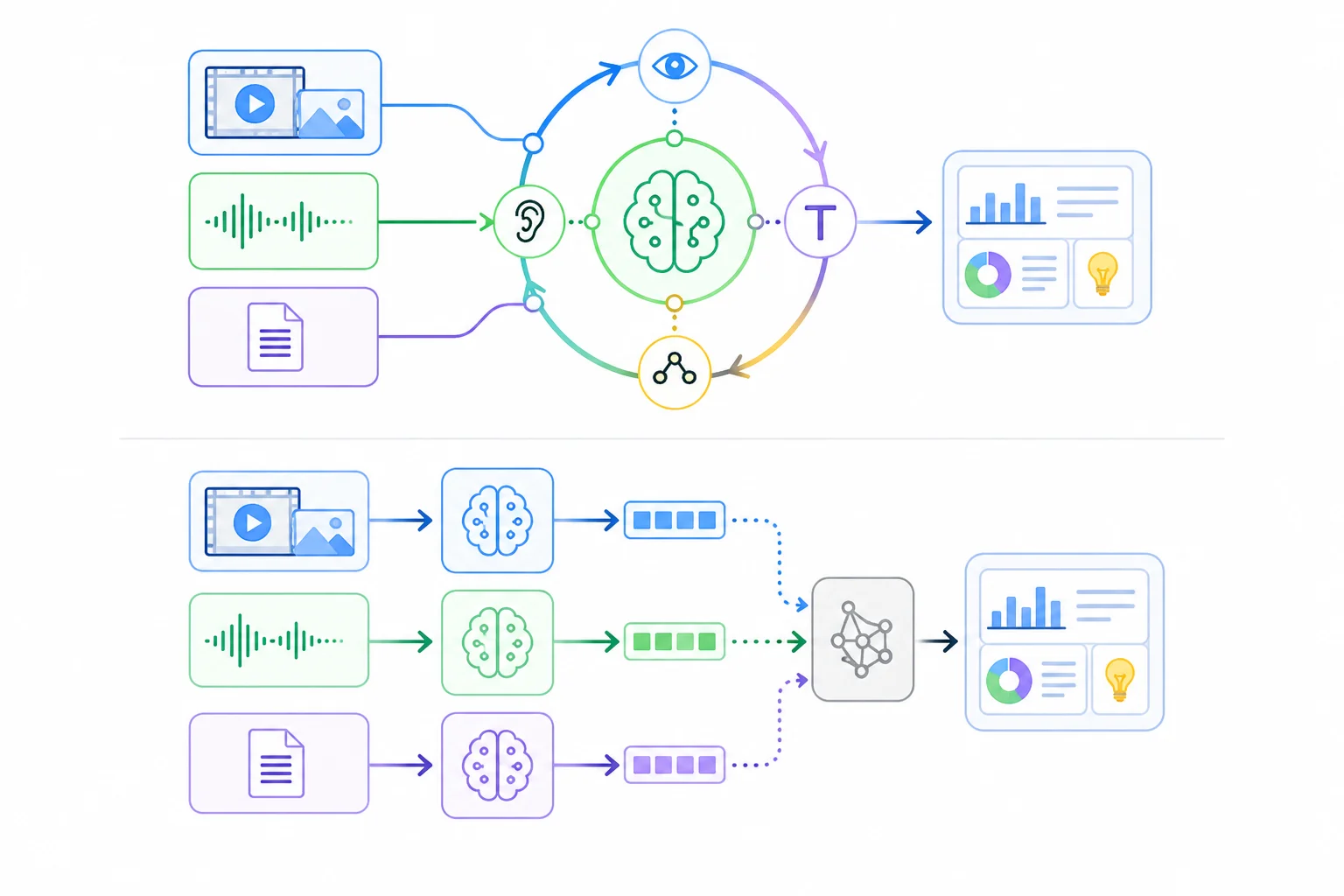
핵심은 보고 듣고 읽는 작업을 하나의 추론 루프 안에 묶었다는 점이다. 기존 에이전트는 화면 캡처를 비전 모델, 음성을 ASR 모델, 텍스트를 언어 모델에 따로 던지고 그 결과를 다시 합쳤다. 그 사이마다 지연이 쌓이고 맥락이 끊겼다. 엔비디아는 비전·음성·언어 인식기를 하나의 30B-A3B 하이브리드 MoE 안으로 흡수해 별도 인지 모델 없이 같은 처리량 기준 9배 높은 throughput을 낸다고 밝혔다.
30B 중 3B만 켜지는 MoE 구조가 만든 차이는 무엇일까?
Nemotron 3 Nano Omni는 30B 파라미터 모델인데, 매 토큰을 처리할 때 활성화되는 건 3B다. 128명의 전문가 중 6명에게만 토큰을 라우팅하는 방식으로, 비전 토큰·오디오 토큰·텍스트 토큰이 같은 아키텍처를 통과하면서도 모달리티에 따라 서로 다른 전문가 집단을 깨운다. 풀어 말하면, 사진을 볼 때 깨우는 뉴런과 음성을 들을 때 깨우는 뉴런을 다르게 잡아둔 셈이다.
내부 구조는 더 들여다볼 만하다. 언어 백본은 Nemotron 3 Nano 30B-A3B이고, 여기에 C-RADIOv4-H 비전 인코더와 Parakeet-TDT-0.6B-v2 오디오 인코더를 가벼운 2-layer MLP 프로젝터로 붙였다. 백본 자체는 23개의 Mamba 선택적 상태공간 레이어, 128개 전문가에 top-6 라우팅을 쓰는 23개 MoE 레이어, 6개의 grouped-query attention 레이어가 교차로 쌓여 있다.
Mamba를 끼워 넣은 건 긴 컨텍스트를 싸게 다루기 위해서다. Transformer만으로 256K 토큰 컨텍스트를 처리하면 메모리가 폭발한다. 상태공간 모델로 시퀀스 처리를 분담하고, 정밀 추론이 필요한 구간만 attention에 맡긴 구조다. 결과적으로 같은 30B 클래스 모델 대비 메모리·계산 효율이 4배까지 올라간다.
보고 듣고 읽는 일을 한 모델이 동시에 한다는 게 무슨 의미인가
가장 손에 잡히는 예시는 화면 녹화 분석이다. 누군가 노트북에서 PDF를 띄워놓고 음성으로 설명을 곁들이는 영상이 있다고 하자. 기존 시스템은 음성을 ASR로 떼어내 텍스트로 바꾸고, 화면 프레임을 OCR과 비전 모델로 따로 분석한 뒤, 둘을 텍스트 단계에서 합쳤다. 음성이 화면 위 어떤 문장을 가리키는지 같은 시점 정보는 그 과정에서 자주 사라졌다.
Nemotron 3 Nano Omni는 영상 프레임과 오디오 토큰을 같은 시퀀스에 끼워 넣고 같이 처리한다. 공유 멀티모달 시퀀스 안에서 네이티브 오디오 처리가 가능해서, 오디오·시각·텍스트 토큰이 함께 모델링된다. 내레이션이 들어간 화면 녹화, 음성이 시각 의미를 바꾸는 비디오 Q&A, 회의 자료가 슬라이드와 함께 나오는 긴 컨텐츠처럼 시간축에 맞춰 멀티모달 추론을 해야 하는 작업에서 결정적이다.
엔비디아는 이 모델을 에이전트의 눈과 귀로 표현한다. 실제로 H Company의 컴퓨터 사용 에이전트는 이 모델을 받아 1920×1080 네이티브 해상도로 화면을 직접 읽고, OSWorld 벤치마크에서 그래픽 인터페이스를 다루는 능력이 크게 올라갔다. OSWorld 점수는 이전 버전 11.1에서 47.4로 뛰었다. 4배 이상이다.
Qwen3-Omni와 정면으로 붙는 이유는 뭘까?
같은 30B-A3B MoE 구조의 오픈 모델은 알리바바 Qwen3-Omni가 이미 있다. 엔비디아 입장에서 Nemotron 3 Nano Omni는 그 자리를 빼앗으러 들어간 모델이다. OCRBenchV2, MMLongBench-Doc, WorldSense, VoiceBench 같은 벤치마크에서 이전 세대 Nemotron Nano V2 VL을 넘어서고, Qwen3-Omni와 동급으로 붙는다. 같은 상호작용 수준에서 처리량은 Qwen3-Omni 대비 9배까지 높다는 게 엔비디아 주장이다.
벤치마크 6개를 쓸어 담았다는 발표가 같이 나왔다. MMlongbench-Doc, OCRBenchV2, WorldSense, DailyOmni, VoiceBench, MediaPerf 여섯 리더보드에서 1위를 기록했다고 엔비디아는 밝혔다. MediaPerf에서는 모든 작업에서 가장 높은 처리량과 비디오 태깅에서 가장 낮은 추론 비용을 기록했다. 단, 독립 검증이 따라붙기 전 수치라는 점은 감안할 부분이다. 출시 직후 자체 평가다.
라이선스 면에서는 Qwen3-Omni가 살짝 앞선다. 두 모델 모두 30B-A3B MoE에 같은 4가지 모달리티(텍스트·이미지·비디오·오디오)를 다룬다. Qwen3-Omni는 Apache 2.0 라이선스로 엔비디아 Open Model Agreement보다 법적으로 약간 더 너그럽다. 엔비디아 모델 약관은 상업 사용을 허용하지만 일부 의무 조항이 따라붙는다. 그래도 가중치·데이터셋·학습 레시피를 모두 공개했다는 점은 동일하게 강력하다.
25GB로 돌릴 수 있다는 게 진짜인가
이 모델이 흔한 데이터센터용 거대 모델과 가장 다른 지점이다. 30B 모델이라고 하면 보통 멀티 GPU 클러스터를 떠올리는데, Nemotron 3 Nano Omni는 한 장짜리 GPU에 들어간다.
4-bit 양자화 버전(Unsloth UD-Q4-K-XL)은 약 25GB의 RAM 또는 VRAM을 쓴다. 8-bit는 36GB, 풀 BF16 버전은 서버 배포 시 약 62GB의 VRAM이 필요하다. RTX 4090(24GB) 사용자도 4-bit 버전은 돌릴 수 있다(빡빡하긴 하다). RTX Pro나 A6000(48GB)이 더 여유 있고, Apple M3/M4 Max 통합 메모리 48GB 또는 64GB 모델은 4-bit와 8-bit 모두 무리 없이 처리한다. 맥북에서 옴니 모델을 돌릴 수 있다는 얘기다.
배포 채널도 셋이다. Hugging Face, OpenRouter, build.nvidia.com에서 NVIDIA NIM 마이크로서비스로 받을 수 있다. 가벼운 오픈 모델로 만들어둔 만큼 NVIDIA DGX Spark를 비롯한 로컬 하드웨어에 배포할 수 있도록 설계됐다. OpenRouter는 무료로 풀려 있어서 API 키만 있으면 바로 호출이 된다.
데이터센터 단위 요구가 빠진다는 건 폭이 넓어진다는 뜻이다. 공장 시각 검사, 로컬 데이터 규제가 강한 의료·금융 워크플로우, 화면을 직접 보면서 일하는 컴퓨터 사용 에이전트. 클라우드 모델 호출에 매번 몇 초씩 기다릴 여유가 없는 작업들이다.
어디까지 보여주는가, 벤치마크 수치로 본 한계
자랑만 정리하면 곤란하다. 한계도 같이 본다. Omni 변형은 이미지·비디오·오디오 인코더가 추가되면서 컨텍스트 윈도우가 줄었다. 텍스트 전용 Nemotron 3 Nano는 1M 토큰까지 받지만, Omni는 256K 토큰이다. 책 한 권을 통째로 넣고 분석시키는 작업은 텍스트 모델 쪽이 여전히 유리하다.
병합형 옴니 모델의 본질적 트레이드오프도 있다. 비전 전용 SOTA, 음성 전용 SOTA를 각각 돌리는 파이프라인보다 단일 모달리티 정확도가 살짝 떨어질 수 있다. 대신 모달리티 사이를 넘나드는 작업에서 격차가 메워진다. 어느 쪽을 택할지는 워크플로우의 모양에 달렸다. 음성만 하루 종일 받아서 텍스트로 옮기는 콜센터라면 ASR 전문 모델이 답이고, 화면+음성+문서를 같이 보는 에이전트라면 옴니 쪽이다.
도입 사례 발표는 빠르게 늘고 있다. 초기 도입 기업은 Aible, Applied Scientific Intelligence(ASI), Eka Care, Foxconn, H Company, Palantir, Pyler이고, Dell Technologies, Docusign, Infosys, K-Dense, Lila, Oracle, Zefr는 평가 단계다. 엔터프라이즈 평가가 보통 6개월 이상 걸리는 걸 감안하면, 출시 시점에 이 정도 명단이 붙는 건 빠른 편이다.
엔비디아가 자체 모델까지 만든다는 게 무슨 뜻인가
엔비디아는 GPU와 인프라를 파는 회사다. 그런데 그 인프라 위에서 돌릴 모델까지 직접 내놓고 있다. 엔비디아 모델은 엔비디아 하드웨어에 최적화되고, 엔비디아 하드웨어는 엔비디아 모델에 최적화된다는 순환 구조다. 구글·아마존·마이크로소프트의 모델+클라우드 결합에 맞서는 풀스택 생태 구축이다.
Nemotron 3 패밀리 자체가 그 흐름의 결과다. 패밀리는 Nano(30B-A3B), Super(120B-A12B), Ultra 셋으로 구성된다. 2026년 4월 29일 기준 Nano(Omni 포함)와 Super가 출시됐고, Ultra는 향후 몇 달 내 공개 예정이다. Nano는 추론 효율과 로컬 배포에 최적화, Super는 멀티 에이전트 협업, Ultra는 다단계 추론이 가장 깊이 들어가는 에이전트 작업의 정확도가 목표다.
다운로드 수치도 엔비디아의 모델 사업이 가설이 아니란 점을 보여준다. Nemotron 3 Nano, Super, Ultra를 포함한 패밀리는 지난 1년간 5천만 회 넘게 다운로드됐다. Hugging Face에서 가장 많은 직원을 둔 조직이 됐다는 부분도 있다. 약 4천 명의 팀원이 등록돼 있다.


댓글
아직 댓글이 없습니다. 첫 댓글을 남겨보세요.